MATRIXX Reference Architecture
A MATRIXX reference configuration runs in Kubernetes clusters in a private or public cloud.
The reference configuration is a multi-cluster deployment that has the following high-level characteristics:
- A Traffic Routing Agent (TRA) in sub-domain routing and disaster recovery mode (TRA-RT/DR) and Network Enabler routes MATRIXX Data Container (MDC) formatted data to the correct sub-domain. The TRA-RT/DR and Network Enabler and can route between clusters to the active MATRIXX Engine.
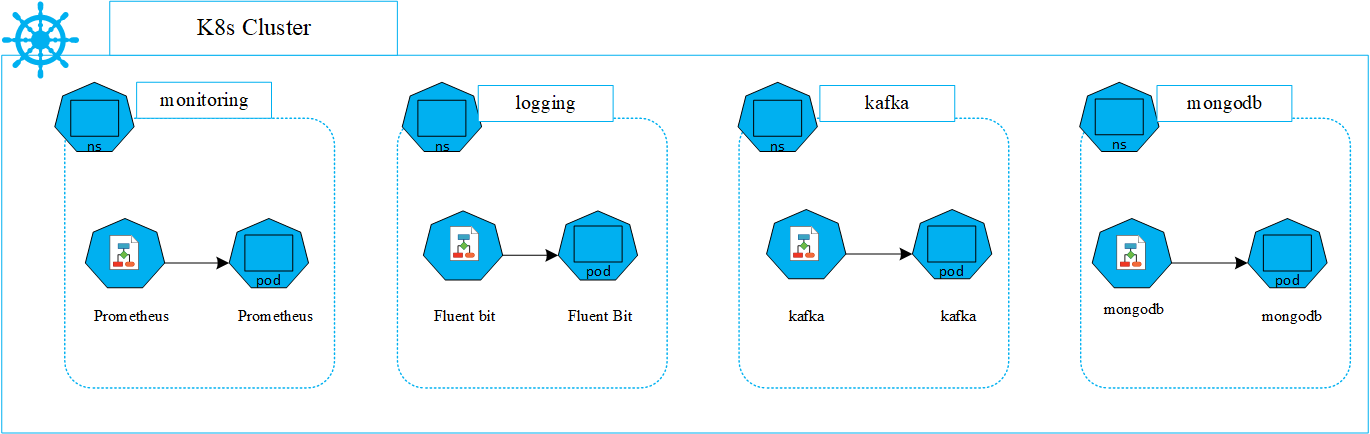
- MATRIXX, Prometheus, and Fluent Bit are installed in separate Kubernetes clusters. An aggregated view of metrics and log data across clusters can be achieved by setting up federation with Prometheus and Fluent Bit.
- ActiveMQ is used to send MDCs from the engine to the MATRIXX gateways and web
apps, and responses are routed
back using ActiveMQ:
- Queues are used to separate messages per sub-domain.
- Broker networks are highly available within the cluster, with at least two instances running.
- ActiveMQ broker networks are not directly connected across clusters. Instead, the engine is configured to connect to all instances of ActiveMQ serving that sub-domain across all clusters. Gateway components only connect to the ActiveMQ broker network in the local cluster.
- MongoDB is installed using the Kubernetes Operator for the reference architecture:
- The engine assumes MongoDB is deployed as a high availability (HA) cluster.
- The Kubernetes Operator only works within a single cluster or namespace. For geographically redundant setups, the Kubernetes operator must be installed on a Kubernetes distribution that can span multiple physical locations, such as Amazon Elastic Kubernetes Service (EKS) over multiple availability zones. If the Kubernetes distribution does not support this, MongoDB must be installed outside the cluster or a hosted solution (Atlas) can be used.
For more information, see the discussion about MongoDB.
Geographical Redundancy
Cloud providers such as Amazon Web Services (AWS) make it possible to run a single Kubernetes cluster across multiple geographical locations. In AWS, these geographies are known as availability zones. Availability zones are data centers that balance being physically close enough to minimize latency with being far enough away to reduce the risk that a fire, earthquake, or other disaster would affect every site hosting cluster components. This is not always available to customers, however, and it does not eliminate the risk of a Kubernetes cluster outage or a regional outage. (An AWS region is a collection of availability zones in a close geographical location.)
The Reference architecture describes a deployment that spans multiple clusters, which would likely be in different geographical locations, like with an AWS multi-region setup.
Ingress Load Balancing
A Kubernetes Ingress is configured for upstream communication with MATRIXX gateways and web apps.
A hardware or software load balancer is required:
- An IP range is defined that is independent of the node IP addresses.
- Individual IP addresses are assigned to applications and components such as MATRIXX Engine, TRA RT/DR, Gateway Proxy, Network Enabler, and SBA Gateway.
- For Proxy components, an Ingress Controller like NGINX is required to route requests on HTTP ports to the correct application depending on the URL.
- For SBA Gateway, an Ingress Controller is required for HTTP/2 load balancing.
MATRIXX Kubernetes Components
Figure 1 shows a low-level component view of the MATRIXX Kubernetes access group.
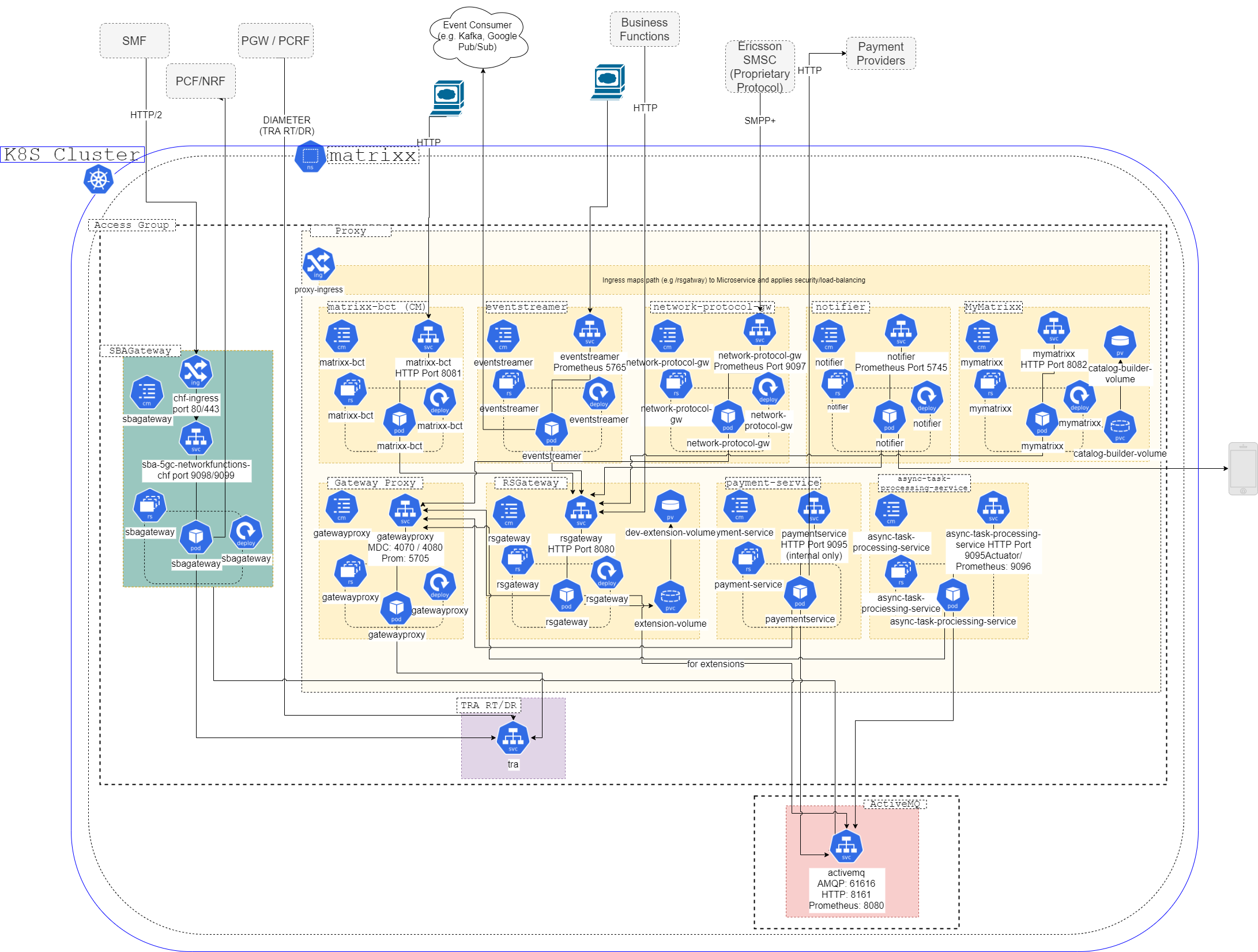
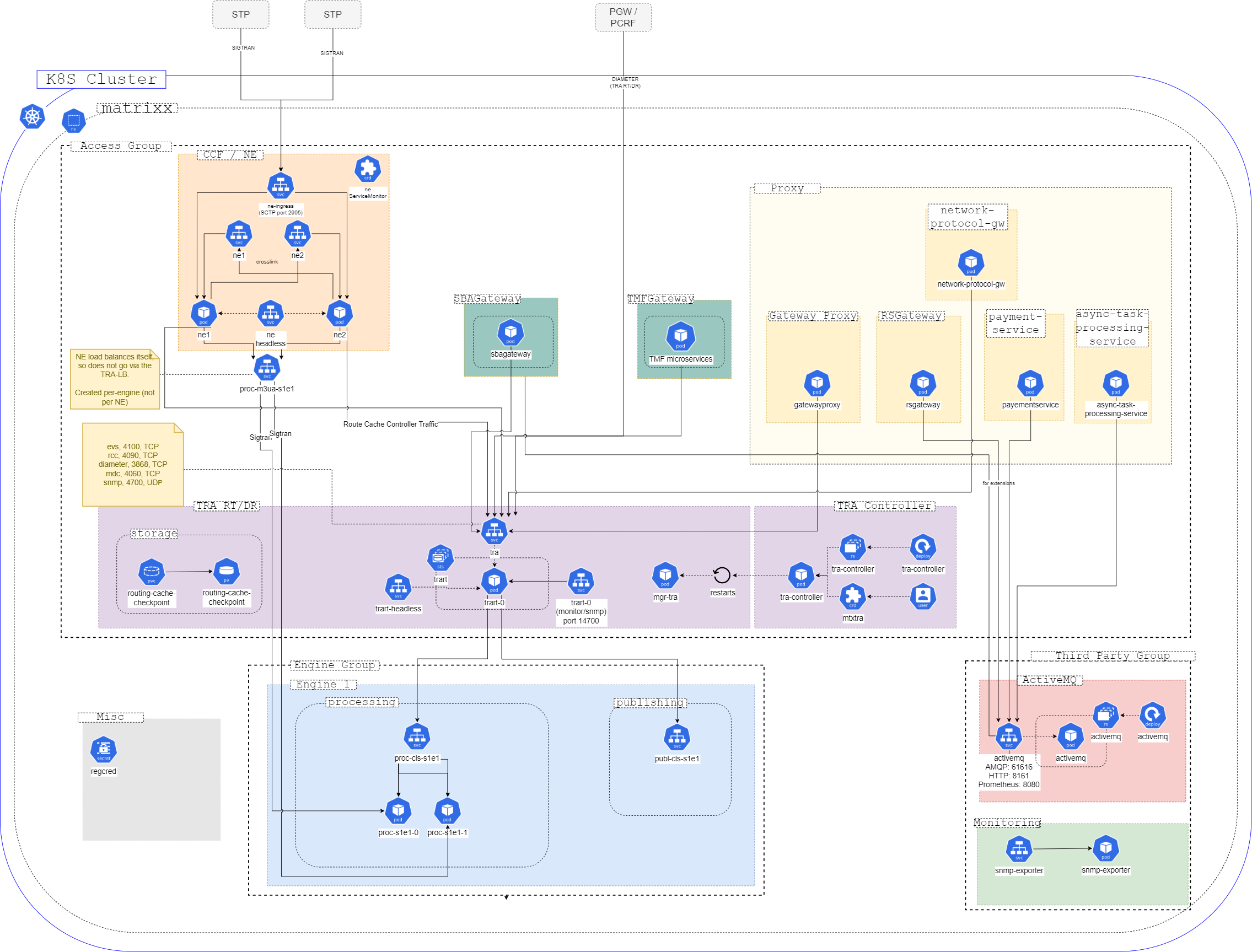
Figure 3 shows a low-level component view of the MATRIXX Kubernetes MATRIXX Engine group.

Figure 4 shows the Kubernetes components that work with, but are not a part of, the MATRIXX Engine group.
Communication Between Clusters
When deployed in a single cluster, the engine controller creates internal services that are front ends for MATRIXX Engine clusters, for example proc-cls-s1e1, publ-cls-s1e1, and ckpt-cls-s1e1. The TRA RT/DR then connects to these processing and publishing services. When deployed in a multi-cluster setup, these services require external connectivity.
In Cluster 1:
- Helm creates internal ClusterIP services for engines within the local cluster: proc-cls-s1e1, publ-cls-s1e1.
- Helm creates ExternalName-type services for engines in the remote cluster: proc-cls-s1e2, publ-cls-s1e2.
The ExternalName service is configured with the domain name of the remote engine cluster, for example, proc-s1e2.cluster2.example.com. This allows the TRA RT/DR to connect using Kubernetes Services, leaving the routing detail to be managed by Kubernetes configuration rather than TRA application configuration.
In Cluster 2:
- The Engine Controller creates services of type LoadBalancer. Due to Kubernetes limitations, two services are required for each Processing and Publishing cluster: one for TCP, one for UDP.
- The LoadBalancer-type Service links to an external IP address from the pool of IP addresses assigned to the load balancer.
- A Central DNS service contains domain names for these IP addresses, such as proc-s1e1-cluster1.
The above is replicated by Network Enabler, with ClusterIP and ExternalName services shown in Cluster 1 and the LoadBalancer services in Cluster 2.
If an Access Group is also deployed in Cluster 2, Helm is used to create ClusterIP and ExternalName services in Cluster 2 that link to the LoadBalancer services in Cluster 1.
