Converting CDRs to ASN.1 Format
Charging data records (CDRs) are processed by the CDR ASN.1 Streamer Kafka client application to convert them from JSON into ASN.1 objects. After the ASN.1 objects are serialized as a binary message using Basic Encoding Rules (BER), they are placed in another Kafka topic for further processing. The ASN.1 sFTP Sink application then writes the message to file before transferring it over Secure FTP (sFTP).
CDR ASN.1 Streamer
Figure 1 shows the CDR ASN.1 Streamer architecture:
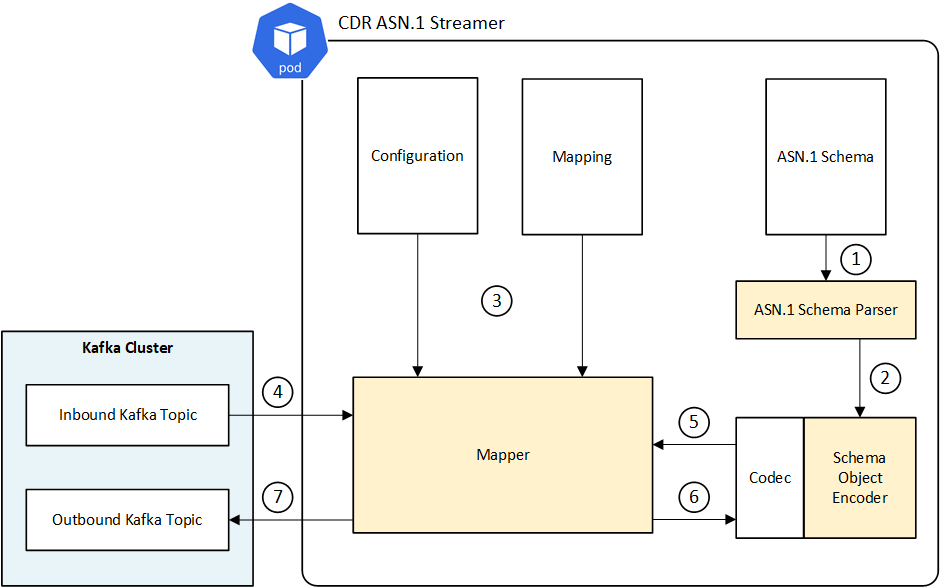
Creation of ASN.1 CDRs in the streamer has the following steps, called out in Figure 1:
- On start up, schema definition files are loaded by the application. An ASN.1 module might be defined in a single file or multiple files.
- The schema parser creates an ASN.1 schema from the schema definition files. This is used to produce mapping objects of the correct type.
- Also on start up, the configuration file and mapping files are loaded. Configuration includes the application information for things such as Kafka topics and read intervals. The mapping files describe the equivalencies between the JSON records and the ASN.1 structure.
- A JSON-format CDR message is received from the Kafka topic.
- ASN.1 mapping information and the JSON-format CDR message are passed to the codec in the Schema Object Encoder. This creates an ASN.1 object structure by passing the mapping information to the schema. The values from the original JSON-format message are set.
- The codec returns a byte buffer containing the BER-encoded binary message.
- The encoded CDR is placed on the outbound Kafka topic for downstream processing.
The schema parser reads one or more ASN.1 schema definition files (as described in 3GPP TS 32.298) and creates an object model based on that definition. The CHF schema is included in the application, though an alternative schema directory can be configured. The parser supports all ASN.1 built-in types, defined types, value assignments, and classes.
The mapper loads configuration and mapping information at start-up, and listens to the configured Kafka topic. Each message is passed to the codec for conversion. The resulting ASN.1 BER encoded message is placed on the outbound Kafka topic.
ASN.1 object types are provided using the Bouncy Castle ASN.1 Provider library. These objects are then encoded into binary format for further processing.
ASN.1 sFTP Sink Application
The ASN.1 sFTP Sink application consumes ASN.1-encoded messages from a Kafka topic and aggregates them in a local cache. Each record is prepended with a header. When configurable conditions are met, such as file size, the records are prepended with a file header and uploaded to an sFTP server. If necessary, the ASN.1 sFTP Sink application can recover missing records. Start and end offsets are stored for each partition and each record in the CDR ASN.1 Streamer outbound Kafka topic so that aggregated records across multiple Kafka partitions can be recovered.
The ASN.1 sFTP Sink application generates a JSON-format metadata file for each ASN.1 file. Each metadata file has all the necessary information about the generated record, including Kafka partition information. Metadata files can include the following fields:
- Node ID
- Topic
- FSN (File Sequence Number)
- RC (Running Count/File issued Number)
- Closure Code
- Partition List
- Start Offset
- End Offset
The following is an example of an ASN.1 metadata file:
{
"nodeID" : "31c21641f6ec",
"topic" : "cdr-route-2",
"fsn" : 0,
"rc" : 1,
"closureCode" : 1,
"topicPartitionsInfo" : {
"1" : {
"startOffset" : 0,
"endOffset" : 10
},
"3" : {
"startOffset" : 0,
"endOffset" : 31
},
"4" : {
"startOffset" : 0,
"endOffset" : 11
}
}
}By default, record recovery is disabled. When enabled, the recovery mode stores metadata in an ASN.1 sFTP Sink persistent volume.
max.poll.interval.ms is 300000 ms or 5 minutes. You can
configure this using the kafka.configuration values. ASN.1 sFTP
Sink presumes it was de-registered and sets the health check status to Down,
becoming unhealthy. This status is detected by Kubernetes, and the pod is restarted
if possible.sftp.internal.writeToDiskRetryMs property.This configuration helps to prevent a disk failure if there is an issue with writing records to the disk.
For information about how the metadata filename is generated, see the discussion about file naming. For configuration information, see the discussion about record recovery configuration and low level configuration properties.